Statistical model
A statistical model is a formalization of relationships between variables in the form of mathematical equations. A statistical model describes how one or more random variables are related to one or more random variables. The model is statistical as the variables are not deterministically but stochastically related. In mathematical terms, a statistical model is frequently thought of as a pair 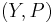 where
where 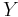 is the set of possible observations and
is the set of possible observations and 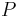 the set of possible probability distributions on . It is assumed that there is a distinct element of which generates the observed data. Statistical inference enables us to make statements about which element(s) of this set are likely to be the true one.
the set of possible probability distributions on . It is assumed that there is a distinct element of which generates the observed data. Statistical inference enables us to make statements about which element(s) of this set are likely to be the true one.
Most statistical tests can be described in the form of a statistical model. For example, the Student's t-test for comparing the means of two groups can be formulated as seeing if an estimated parameter in the model is different from 0. Another similarity between tests and models is that there are assumptions involved. Error is assumed to be normally distributed in most models.[1]
Contents |
Formal definition
A Statistical model, 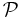 , is a collection of probability distribution functions or probability density functions (collectively referred to as distributions for brevity). A parametric model is a collection of distributions, each of which is indexed by a unique finite-dimensional parameter:
, is a collection of probability distribution functions or probability density functions (collectively referred to as distributions for brevity). A parametric model is a collection of distributions, each of which is indexed by a unique finite-dimensional parameter: 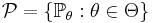 , where
, where 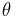 is a parameter and
is a parameter and 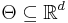 is the feasible region of parameters, which is a subset of d-dimensional Euclidean space. A statistical model may be used to describe the set of distributions from which one assumes that a particular data set is sampled. For example, if one assumes that data arise from a univariate Gaussian distribution, then one has assumed a Gaussian model:
is the feasible region of parameters, which is a subset of d-dimensional Euclidean space. A statistical model may be used to describe the set of distributions from which one assumes that a particular data set is sampled. For example, if one assumes that data arise from a univariate Gaussian distribution, then one has assumed a Gaussian model: 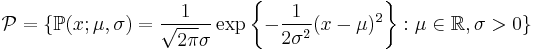 .
.
A non-parametric model is a set of probability distributions with infinite dimensional parameters, and might be written as 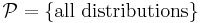 . A semi-parametric model also has infinite dimensional parameters, but is not dense in the space of distributions. For example, a mixture of Gaussians with one Gaussian at each data point is dense is the space of distributions. Formally, if d is the dimension of the parameter, and n is the number of samples, if
. A semi-parametric model also has infinite dimensional parameters, but is not dense in the space of distributions. For example, a mixture of Gaussians with one Gaussian at each data point is dense is the space of distributions. Formally, if d is the dimension of the parameter, and n is the number of samples, if 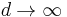 as
as 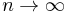 and
and 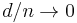 as , then the model is semi-parametric.
as , then the model is semi-parametric.
Model comparison
Models can be compared to each other. This can either be done when you have done an exploratory data analysis or a confirmatory data analysis. In an exploratory analysis, you formulate all models you can think of, and see which describes your data best. In a confirmatory analysis you test which of your models you have described before the data was collected fits the data best, or test if your only model fits the data. In linear regression analysis you can compare the amount of variance explained by the independent variables, R2, across the different models. In general, you can compare models that are nested by using a Likelihood-ratio test. Nested models are models that can be obtained by restricting a parameter in a more complex model to be zero.
An example
Length and age are probabilistically distributed over humans. They are stochastically related, when you know that a person is of age 7, this influences the chance of this person being 6 feet tall. You could formalize this relationship in a linear regression model of the following form: lengthi = b0 + b1agei + εi, where b0 is the intercept, b1 is a parameter that age is multiplied by to get a prediction of length, ε is the error term, and i is the subject. This means that length starts at some value, there is a minimum length when someone is born, and it is predicted by age to some amount. This prediction is not perfect as error is included in the model. This error contains variance that stems from sex and other variables. When sex is included in the model, the error term will become smaller, as you will have a better idea of the chance that a particular 16-year-old is 6 feet tall when you know this 16-year-old is a girl. The model would become lengthi = b0 + b1agei + b2sexi + εi, where the variable sex is dichotomous. This model would presumably have a higher R2. The first model is nested in the second model: the first model is obtained from the second when b2 is restricted to zero.
Classification
According to the number of the endogenous variables and the number of equations, models can be classified as complete models (the number of equations equals to the number of endogenous variables) and incomplete models. Some other statistical models are the general linear model (restricted to continuous dependent variables), the generalized linear model (for example, logistic regression), the multilevel model, and the structural equation model.[2]
See also
References
- ^ Field, A. (2005). Discovering statistics using SPSS. Sage, London.
- ^ Adèr, H.J. (2008). Chapter 12: Modelling. In H.J. Adèr & G.J. Mellenbergh (Eds.) (with contributions by D.J. Hand), Advising on Research Methods: A consultant's companion (pp. 271-304). Huizen, The Netherlands: Johannes van Kessel Publishing.